


クラスタリングとは
クラスタリングとは、ある集合を非類似度に従って、部分集合(クラスター)に分けることです。

「非類似度」とは、どれくらい似ているか(似ていないか)ということです!
非類似度の定義の仕方は様々です。例えば、以下のような図形の集合があったとしましょう。
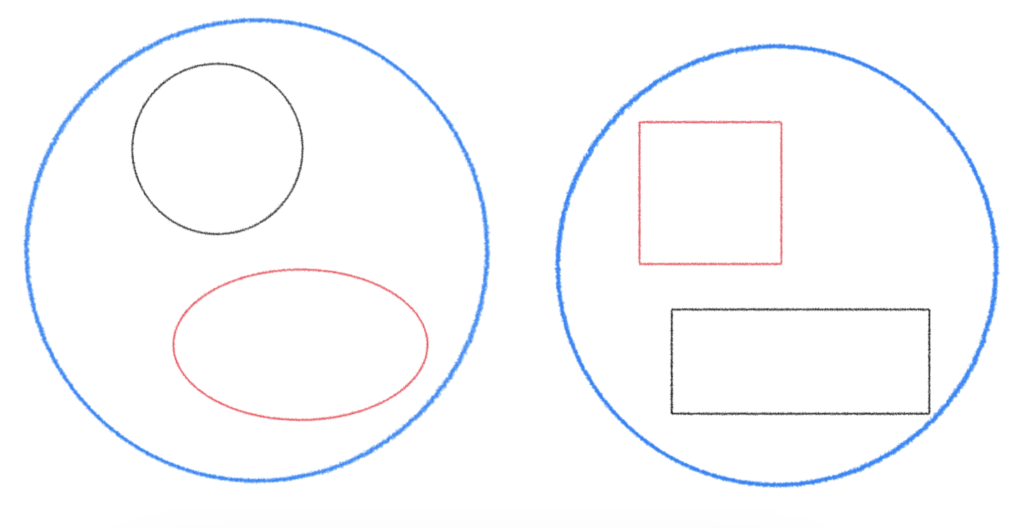
「形」を基準にすると、
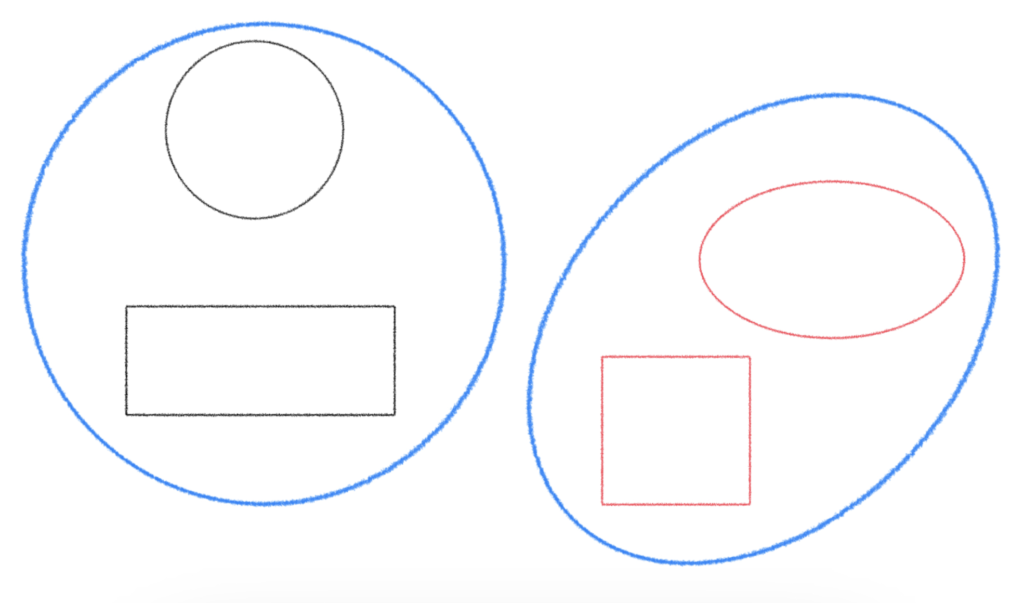
「色」を基準にすると、
このように、分けるための基準を非類似度、あるいは類似度や単に距離と呼ぶこともあります。
クラスタリングには大きく 2 つに分けられます。
・階層的手法
樹形図によって表現されるような、集団の系統発生的な構造をさぐることによってクラスターを構成しようとするものです。各個体を
・非階層的手法
クラスターの妥当性の基準として、クラスター内の変動をできるだけ小さくし、クラスター間の変動をできるだけ大きくしようとし、あらかじめクラスター数が決まっているような手法です。
クラスタリングを考える上で重要な
・個体間の類似度/非類似度
・算法(アルゴリズム)
・評価
個体間の類似度
扱うデータによって、類似度(距離)の定義は様々ですが、一般的には以下の
ある個体を、
このように、扱うデータによって様々な距離が存在しています!
算法(アルゴリズム)
クラスター分析には、さまざまなアルゴリズムが存在します。ここでは、代表的なアルゴリズムとして、K-means法、階層型クラスタリング、DBSCANなどが挙げられますが、今回は、非階層的手法に絞って紹介していきます。
K-means法は、非階層的クラスタリング手法の中でも最も広く使われる手法で、最小二乗法に基づいてクラスターを構築します。理論的な視点からK-means法の手順を解説し、その応用例も示します。
K-means法の理論的手順
K-meansでは、最初にデータ空間において
次に、各データポイントが最も近いセントロイドに割り当てられます。これを行う際、各データ点
データ点は、この距離が最も小さいセントロイドを持つクラスターに割り当てられます。
クラスターの割り当てが終わった後、それぞれのクラスターの中心(セントロイド)が再計算されます。新しいセントロイドは、そのクラスターに属するデータ点の平均値として計算されます。
ここで、
STEP2とSTEP3を繰り返し、クラスター割り当てやセントロイドの位置が変わらなくなる、つまり、収束条件が満たされるまで処理を続けます。収束条件には以下のようなものがあります。
・クラスターの割り当てが変わらなくなる
・セントロイドの移動距離が小さくなる
K-meansの目標は、全てのデータポイントのセントロイドへの距離の二乗和を最小化することです。
この関数Jを最小にするようにクラスターを構成することが、K-meansの最終目的です。
K-means法の応用例
応用例1: 顧客セグメンテーション
マーケティング分野では、K-means法を用いて顧客を特定の属性に基づいてグループ化し、マーケティング戦略を最適化することが一般的です。たとえば、顧客の購買履歴や年齢、収入などのデータを基に、同じ特性を持つ顧客をクラスターに分けることができます。これにより、各グループに対してターゲットを絞ったキャンペーンやサービスを提供できるようになります。
応用例2: 画像圧縮
K-means法は、画像圧縮にも応用されます。画像をピクセルの集まりとして扱い、ピクセルの色をK個の代表的な色(クラスターのセントロイド)に分類することで、色の数を減らして画像を圧縮します。この手法は、コンピュータビジョンや画像処理の分野でよく使用されます。
応用例3: 異常検知
K-means法は異常検知にも用いられます。例えば、センサーデータや金融取引データなどに対してK-means法を適用し、データをクラスターに分類します。通常のデータはクラスターの中心に近く、異常なデータはクラスターの外れに位置するため、クラスターのセントロイドから遠く離れたデータを異常として検出することができます。
クラスターの評価方法
クラスター分析の結果を評価するための手法について説明します。例えば、シルエット係数やダビッド・バウディン指数など、クラスターの質を測る指標があります。これらの評価方法を使用して、クラスターの分割が適切かどうかを判断するプロセスを解説します。
おわりに
さいごまで読んでいただきありがとうございました!
『統計の扉』で書いている記事
- 高校数学の解説
- 公務員試験の数学
- 統計学(統計検定2級レベル)
ぜひご覧ください!
数学でお困りの方は、コメントやXでご連絡ください。(Xはこちら)
私自身、数学が得意になれたのはただ運が良かったんだと思っています。たまたま親が通塾させることに積極的だったり、友達が入るって理由でそろばんに入れたり、他の科目が壊滅的だったおかげで数学が(相対的に)得意だと勘違いできたり。
”たまたま”得意になれたこの恩を、今数学の学習に困っている人に還元できたらなと思っています。お金は取りません。できる限り(何百人から連絡が来たら難しいかもですが…)真摯に向き合おうと思っていますのでオアシスだと思ってご連絡ください。