


統計学におけるサンプリングの重要性とその種類
統計学において、母集団全体のデータをすべて調査することは、現実的に不可能な場合がほとんどです。
例えば、国全体の消費者の購買行動や、企業の全顧客の満足度を直接調査することは、時間やコストの面からも非常に困難です。そこで、サンプリング(標本抽出)が重要な役割を果たします。
サンプリングを通じて、母集団から一部のデータを抽出し、それを基に全体を推測することができます。
この記事では、サンプリングの必要性と、いくつかの主要なサンプリング方法について解説します。どの手法が最適かは、調査の目的や母集団の特性に依存しますが、適切なサンプリングを選ぶことで、限られたリソースで信頼性の高いデータを得ることができます。
サンプリングの必要性
サンプリングの最大の利点は、コストや時間の削減です。
母集団全体を調査する「全数調査」は、リソースが無尽蔵にあれば理想的ですが、実際には不可能なことが多いです。
一方、サンプリングを行うことで、限られたデータから母集団全体を推測でき、リソースを効率的に使用することが可能になります。また、適切なサンプリングを行えば、全数調査と同じ程度の精度を持つ推論が可能です。
さらに、サンプリングはデータの管理や解析を簡単にします。大量のデータを扱う場合、データの取り扱いや処理が複雑になり、誤りの可能性も増えます。標本を取ることで、これらのリスクを減らし、データ分析を効率化することができます。
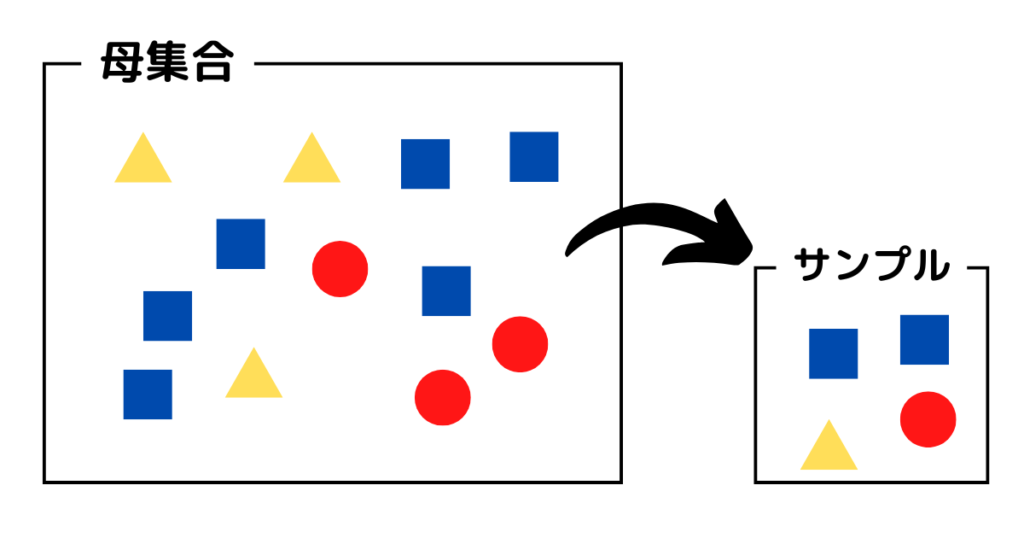
例)
・全数調査
母集団になにが入ってるのか?を全て調査すること。
・サンプリング
サンプルとしていくつかを抽出し、そこから母集合の構造を推測すること。下の例だと「青が少し多いかもな」と予想できます。
サンプリングの種類とその特徴
「全数調査」が全体を推測するなら最適な方法です。
しかし、データが大きくなればなるほどそれは非現実的になります。
そこで、全数調査の精度にはならずとも、時間やリソースをなるべくかけないいくつかのサンプリングを紹介していきます。
1. 単純ランダムサンプリング
単純ランダムサンプリングは、母集団から無作為にデータを選び出す最も基本的な手法です。すべての要素が等しい確率で選ばれるため、バイアスが少なく、母集団全体を偏りなく反映できることが期待されます。
メリット
偏りが少なく、理論的に推測の精度が高い。
デメリット
母集団が非常に大きい場合、ランダム抽出がコストや時間的に難しい。
適用例
例えば、無作為に選んだ消費者から購入履歴を集める場合に有効です。
2. 系統的サンプリング
系統的サンプリングは、一定の間隔で母集団から要素を抽出する方法です。最初にランダムに選んだ要素から、規則的な間隔で標本を取っていきます。
メリット
手順が簡単で、迅速に標本を取得できる。
デメリット
母集団に周期性がある場合、バイアスが生じる可能性がある。
例)季節変動のあるデータのように気温や売上などが季節ごとに周期的に変動するデータの場合
適用例
人口統計や生産ラインの品質管理など、特定の順序でデータを取りやすい場合に適しています。
3. 層別サンプリング
層別サンプリングは、母集団を特定の属性に基づいて層に分け、各層から無作為にデータを抽出する方法です。たとえば、年齢や性別ごとに層を分け、それぞれからサンプルを取ることで、層ごとの特性を考慮した調査が可能です。
メリット
層ごとに母集団を正確に反映でき、精度の高い推論が可能。
デメリット
層の定義や標本の分割に手間がかかる。
適用例
複数の層に分かれた母集団(例: 年齢層や所得層)を調査する場合に適しています。
4. クラスタサンプリング
クラスタサンプリングは、母集団をクラスタと呼ばれるサブグループに分け、その中からいくつかのクラスタを無作為に選んで調査する方法です。選ばれたクラスタ内のすべての要素を調査するため、全体の中から特定の部分を詳細に調べることができます。
メリット
広範囲にわたる母集団からサンプルを取る場合に、移動コストや時間を節約できる。
デメリット
選ばれたクラスタが全体を代表しないリスクがある。
適用例
地理的に分散した母集団(例: 国や地域の調査)での使用に適しています。
5. 多段階サンプリング
多段階サンプリングは、複数の段階にわたってサンプリングを行う手法です。たとえば、まず地域ごとにクラスタを選び、その後各地域内でランダムにデータを抽出するというプロセスです。
メリット
非常に大きな母集団から効率的に標本を抽出できる。
デメリット
複雑な手法であるため、手順が増えるごとに誤差が蓄積するリスクがある。
適用例
国家レベルの大規模調査など、段階的に絞り込みが必要な場合に有効です。
まとめ
サンプリングは、効率的かつ正確なデータ収集のために欠かせない手法です。
しかし、どのサンプリングも全数調査に比べると少なからずバイアスがかかってしまいます。限られたリソースの中で、調査の目的や母集団の特性に応じて適切なサンプリング方法を選ぶことが重要です。
単純ランダムサンプリングや系統的サンプリングのような基本的な方法から、層別サンプリングやクラスタサンプリングのような応用的な手法まで、それぞれの特性を理解し、目的に応じて活用しましょう。
さいごまで読んでいただきありがとうございました!
『統計の扉』で書いている記事
- 高校数学の解説
- 公務員試験の数学
- 統計学(統計検定2級レベル)
ぜひご覧ください!
数学でお困りの方は、コメントやXでご連絡ください。(Xはこちら)
私自身、数学が得意になれたのはただ運が良かったんだと思っています。たまたま親が通塾させることに積極的だったり、友達が入るって理由でそろばんに入れたり、他の科目が壊滅的だったおかげで数学が(相対的に)得意だと勘違いできたり。
”たまたま”得意になれたこの恩を、今数学の学習に困っている人に還元できたらなと思っています。お金は取りません。できる限り(何百人から連絡が来たら難しいかもですが…)真摯に向き合おうと思っていますのでオアシスだと思ってご連絡ください。